In case you need to provide Spark with resources from a different AWS account, I found that quite tricky to figure out.
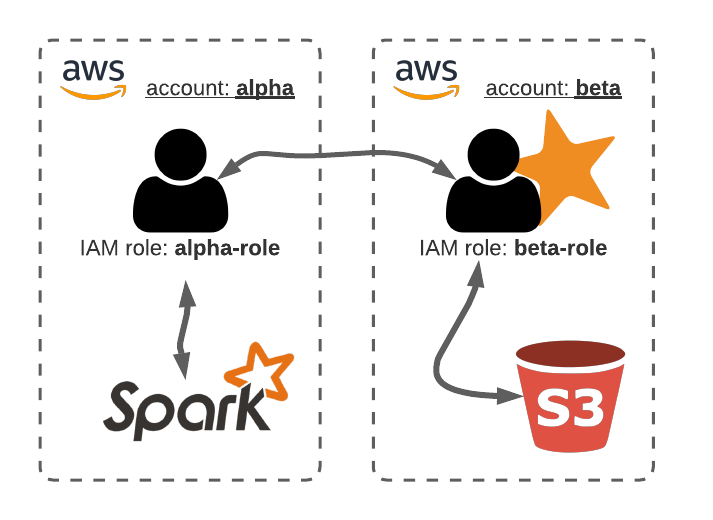
Let’s assume you have two AWS accounts: the alpha account where you run Python with IAM role alpha-role and access to the Spark cluster; and the beta account where you have the S3 bucket you want to get access to. You could give S3 read access to the alpha-role, but it is more persistent and easier to manage by creating an access-role in the beta account that can be assumed by the alpha-role.
1. Create the access role
Start with creating a policy, e.g. named “read-access-beta-bucket-dataset” with the following JSON content:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:ListBucket", "s3:GetBucketLocation"],
"Resource": "arn:aws:s3:::beta-bucket-dataset-eu-west-1"
},
{
"Effect": "Allow",
"Action": ["s3:GetObject"],
"Resource": "arn:aws:s3:::beta-bucket-dataset-eu-west-1/*"
}
]
}
Now create the IAM role beta-role and attach the above created policy. To establish trust between the alpha-role and this newly created access role, include the alpha-role as a trusted entity to the trust relationship of the access role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:sts::xxxxxxxxxxxx:role/alpha-role"
},
"Action": "sts:AssumeRole"
}
]
}
2. Test the access
From a terminal in the alpha environment you can now test the bucket access by assuming the beta-role. Make sure to install the aws client with pip install awscli. Use the following command to get temporary credentials of the beta-role:
aws sts assume-role --role-arn "arn:aws:iam::xxxxxxxxxxxx:role/beta-role" --role-session-name "test-acess"
Create three environment variables to assume the IAM role:
export AWS_ACCESS_KEY_ID=RoleAccessKeyID
export AWS_SECRET_ACCESS_KEY=RoleSecretKey
export AWS_SESSION_TOKEN=RoleSessionToken
You should now be able to list and get objects from the bucket:
aws s3 ls s3://beta-bucket-dataset-eu-west-1
aws s3 ls s3://beta-bucket-dataset-eu-west-1 --recursive
You can revert to the original role by unsetting the environmental variables:
unset AWS_ACCESS_KEY_ID AWS_SECRET_ACCESS_KEY AWS_SESSION_TOKEN
3. Spark access
Finally we can give cross-account read access to Spark with temporary credentials. Note that the specific AWS and Hadoop jars are really brittle accross versions, in my case I ran with Spark 2.4.6 and Hadoop 2.9.2.
from pyspark.sql import SparkSession
import boto3
role_session_name = "s3read"
role_arn = "arn:aws:iam::xxxxxxxxxxxx:role/beta-role"
duration_seconds = 60*15 # durations of the session in seconds
# obtain the temporary credentials
credentials = boto3.client("sts").assume_role(
RoleArn=role_arn,
RoleSessionName=role_session_name,
DurationSeconds=duration_seconds
)['Credentials']
spark = SparkSession \
.builder \
.enableHiveSupport() \
.appName("test bucket access") \
.config("spark.hadoop.fs.s3.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") \
.config("spark.jars.packages", "com.amazonaws:aws-java-sdk:1.11.199,org.apache.hadoop:hadoop-aws:2.9.2") \
.config("spark.hadoop.fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider") \
.config("spark.hadoop.fs.s3a.access.key", credentials['AccessKeyId']) \
.config("spark.hadoop.fs.s3a.secret.key", credentials['SecretAccessKey']) \
.config("spark.hadoop.fs.s3a.session.token", credentials['SessionToken']) \
.getOrCreate()
df = spark.read \
.option("inferSchema", "true") \
.option("header", "true") \
.csv("s3a://beta-bucket-dataset-eu-west-1/*.csv")